


近日使用采集工具QueryList V3,好不容易将代码写出来,结果发现一旦数量多了起来,就直接卡死。。。
无奈之下又得升级到V4版本重新写。。。虽说卡顿问题依旧有,但比起上个版本还要好得多,就是代码又复杂了点。
接下来就以小刀网为例子:
绿色软件地址:https://xd.x6d.com/html/23.html
然后获取列表li的div如图:
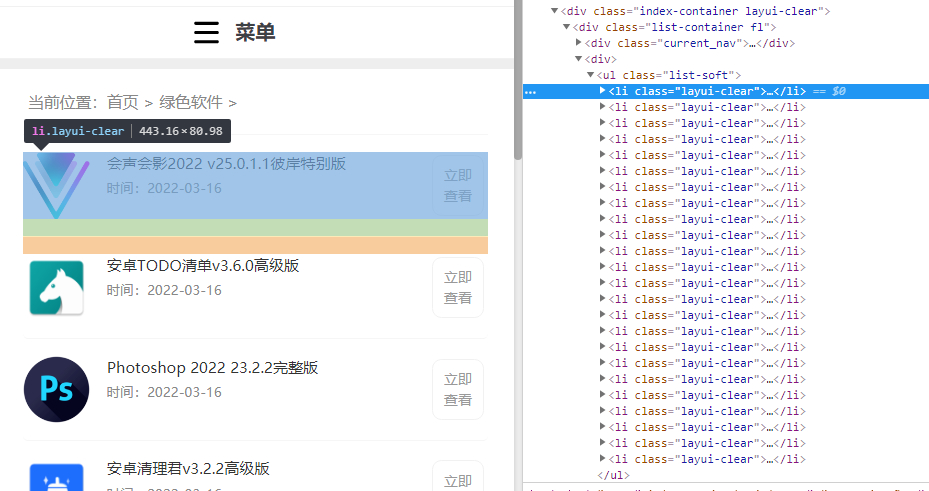
得出就是:.list-soft li
接着就是链接与标题了。
因为V4版本的是直接从定位列表li那里开始的,所以我们直接填div点

结果就是:
链接:.list-img a
标题:.list-info a.soft-title 也可以是链接
封图:.list-img img
然后到了内容页:
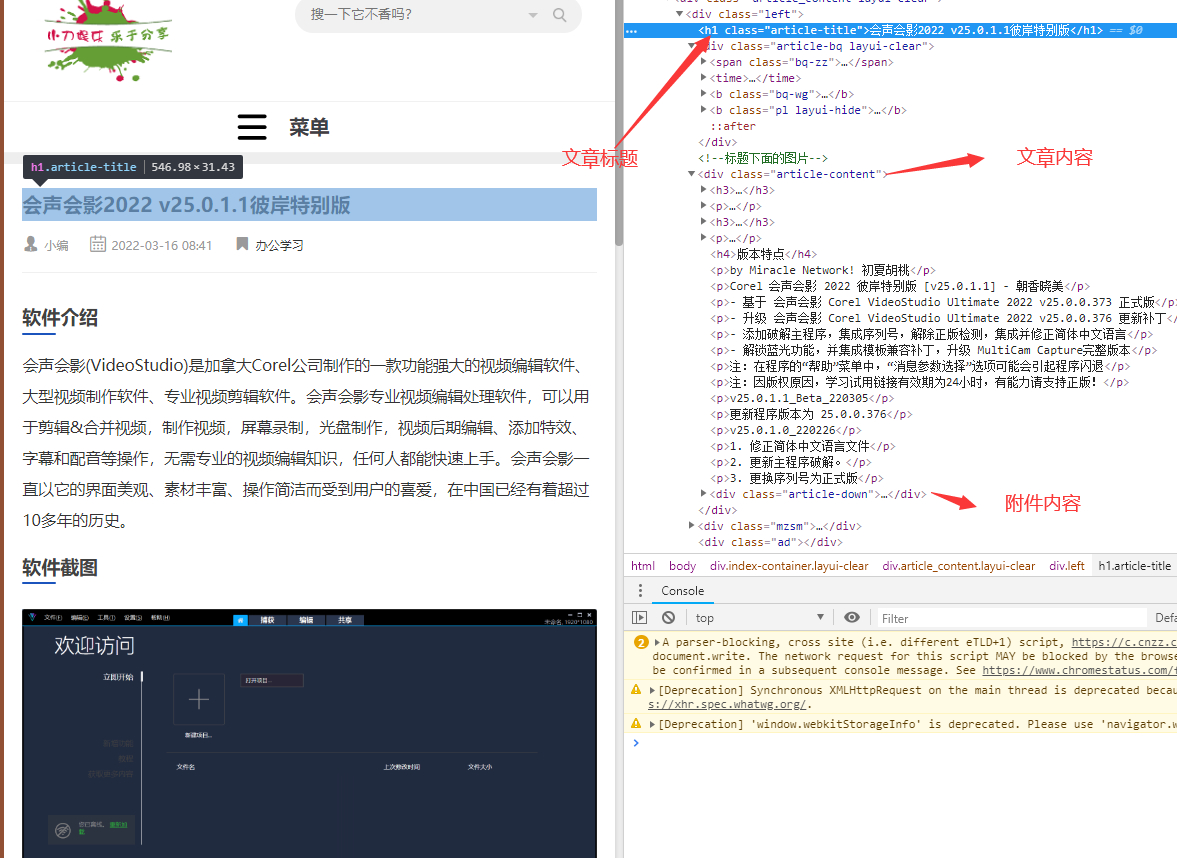
这里因为不是循环列表的,所以要尽可能的填上相对的div,不然其他位置也有相同div就容易出错。
结果:
标题:.article-title 这里是为了覆盖列表的标题,防止有其他文字
内容:.article-content
如果要将附件直接插进内容的话,就不需要过滤内容反之填上:div a -.copyright -.article-down
这里是过滤掉DIV属性,和链接、版权说明、下载链接
附件是循环得,所以规则是按照列表文章那种方式获取定位
附件:.article-down a 这里如果不添加附件的话就不填,
上面附件定位填的话就填取值:data-url

这个得看附件链接是什么属性的,是href就选择href
提取码也是一样,这里没有就不说了。
最终表格如下:

